整体架构概览
在开始写代码之前,理解整个系统如何协作至关重要。您的 PHP 智能体将不仅仅是调用 API,而是成为一个拥有长期记忆(知识库)和思维逻辑(提示词)的系统
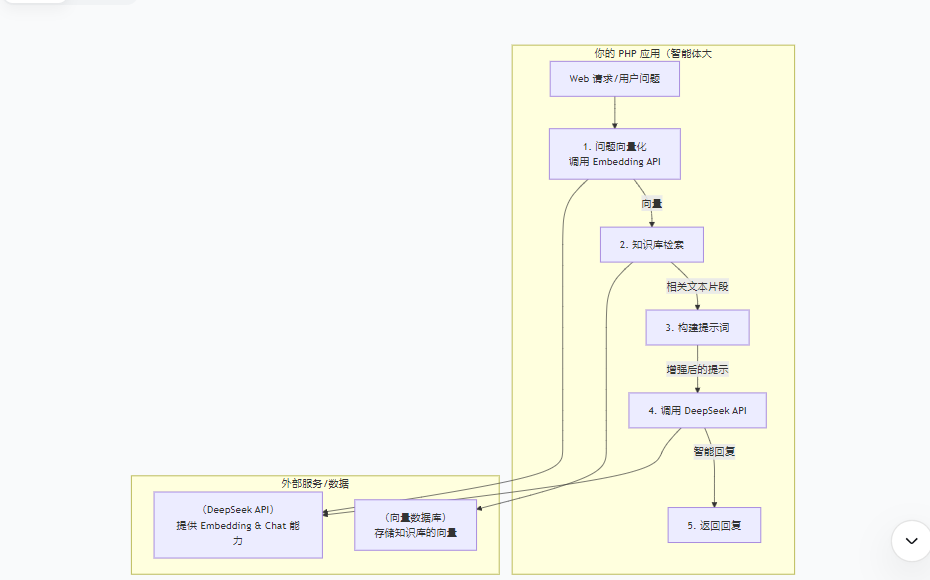
这个流程图展示了整个智能体的核心工作流程:先将用户问题向量化,再用其检索知识库,将检索结果与原始问题组合成增强提示词,最后发送给大模型得到最终回复。
第一部分:核心组件与准备工作
你需要以下几个核心部分:
DeepSeek API 账号与密钥:访问 DeepSeek 官网 注册并获取你的 API Key。
PHP 环境:确保你的 PHP 环境版本在 7.4 以上,并启用 cURL 扩展。
向量数据库:是的,你需要一个向量数据库。 虽然理论上你可以用 PHP 和 MySQL 手动计算余弦相似度,但对于任何严肃的项目,这都非常低效且不实用。向量数据库为此类检索进行了高度优化。
推荐选择:
Chroma: 轻量级、开源、易于上手,适合原型和中小项目。
Weaviate: 功能强大,开源,支持多种模块。
Qdrant: 性能优异,Rust 编写,开源。
Pinecone: 全托管服务,无需运维,但付费。
知识库数据:你要让智能体学习的文档、PDF、网页内容等。
第二部分:知识库与向量化
这是让你的智能体变得“聪明”和“专业”的关键。
步骤 1: 数据预处理与分块
原始文档不能直接使用,需要清洗和分割。
清洗:去除无关的格式、HTML 标签等,提取纯文本。
分块:将长文本分割成更小的段落(例如 256-512 个字符)。这是因为 Embedding 模型有输入长度限制,并且检索时需要返回最相关的片段,而不是整个文档。
分块策略:按段落、按标题、使用滑动窗口等。合理的分块能极大影响检索质量。
步骤 2: 文本向量化
什么是向量化:使用 DeepSeek 提供的 Embedding API,将每一段文本转换成一个高维数值向量(一长串数字,例如 1536 维)。这个向量在数学上代表了文本的“语义”。
如何操作:
调用 DeepSeek 的 Embedding 端点 (
https://api.deepseek.com/v1/embeddings)。将分块后的文本数组发送过去。
获取返回的向量数组。
PHP 代码示例:文本向量化
<?phpfunction get_embedding($text, $api_key) {
$url = 'https://api.deepseek.com/v1/embeddings';
$headers = [
'Authorization: Bearer ' . $api_key,
'Content-Type: application/json',
];
$data = [
'input' => $text, // 可以是字符串或字符串数组
'model' => 'deepseek-embedding', // 确认最新的embedding模型名称
];
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
$result = json_decode($response, true);
if (isset($result['data'][0]['embedding'])) {
return $result['data'][0]['embedding']; // 返回单个向量的数组
} elseif (isset($result['data'])) {
// 如果是批量处理,返回所有向量的数组
return array_column($result['data'], 'embedding');
} else {
throw new Exception("Embedding API 错误: " . $response);
}}// 用法示例$api_key = '你的_DEEPSEEK_API_KEY';$chunk_text = "这是你知识库中的一段文本...";$vector = get_embedding($chunk_text, $api_key);// $vector 现在是一个浮点数数组,例如 [0.123, -0.456, 0.789, ...]?>步骤 3: 存储到向量数据库
将文本块和其对应的向量一起存储到向量数据库中。
通常需要存储三条信息:
id: 唯一标识。vector: 上一步得到的向量。text或metadata: 原始的文本块以及其他元数据(如来源文件、标题等)。
以 Chroma 为例的概念性步骤(具体代码取决于你用的客户端):
创建或连接一个集合。
将
ids,embeddings(vectors),metadatas(包含原始文本) 批量添加到集合中。
第三部分:提示词与知识库的交互 - 推理过程
这是智能体“思考”的核心。流程是:用户提问 -> 检索知识库 -> 构建增强提示词 -> 调用 DeepSeek Chat API -> 返回答案。
步骤 1: 用户提问并向量化检索
接收用户输入的问题
$user_query。使用同样的 Embedding 模型将
$user_query转换为向量。用这个查询向量去向量数据库中执行相似性搜索(例如余弦相似度)。
数据库返回最相似的 K 个文本块(例如 top 3)。
步骤 2: 构建系统提示词
这是最巧妙的一步。你不能直接把问题和答案扔给模型,而是要“引导”它。
系统提示词:定义模型的角色和回答规则。
上下文注入:将上一步检索到的相关文本块,作为“上下文”插入到提示词中。
提示词模板示例:
你是一个专业的客服助手,请严格根据以下【已知信息】来回答用户的问题。如果你不知道答案,请直接说“根据已知信息无法回答该问题”,不要编造答案。
#【已知信息】
{context}
#【用户问题】
{question}PHP 代码示例:构建提示词并调用 Chat API
<?phpfunction ask_deepseek($user_query, $retrieved_texts, $api_key) {
$url = 'https://api.deepseek.com/v1/chat/completions';
// 1. 构建系统提示词,注入检索到的知识
$context = implode("\n\n", $retrieved_texts); // 将检索到的多个文本块合并
$system_message = "你是一个专业的助手,请严格根据以下【已知信息】来回答用户的问题。\n\n#【已知信息】\n" . $context . "\n\n如果你不知道答案,请直接说“根据已知信息无法回答该问题”,不要编造答案。";
$headers = [
'Authorization: Bearer ' . $api_key,
'Content-Type: application/json',
];
// 2. 构建请求数据
$data = [
'model' => 'deepseek-chat', // 例如 deepseek-v2
'messages' => [
['role' => 'system', 'content' => $system_message],
['role' => 'user', 'content' => $user_query]
],
'temperature' => 0.1, // 低温度,让答案更确定,更依赖于知识库
'max_tokens' => 2000
];
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
$httpCode = curl_getinfo($ch, CURLINFO_HTTP_CODE);
curl_close($ch);
if ($httpCode !== 200) {
throw new Exception("API 请求失败: " . $response);
}
$result = json_decode($response, true);
return $result['choices'][0]['message']['content'];}// --- 整体流程示例 ---$api_key = "你的_DEEPSEEK_API_KEY";$user_question = $_POST['question']; // 从Web表单获取问题// 1. 将用户问题向量化$query_vector = get_embedding($user_question, $api_key);// 2. 查询向量数据库 (这里用伪代码,取决于你用的向量DB客户端)$retrieved_chunks = $vectorDBClient->query($query_vector, $top_k=3);// $retrieved_chunks 是一个数组,包含元数据,我们需要里面的文本$retrieved_texts = array_column($retrieved_chunks, 'text');// 3. 调用上面定义的函数,获取最终答案$final_answer = ask_deepseek($user_question, $retrieved_texts, $api_key);// 4. 将 $final_answer 输出给用户echo $final_answer;?>第四部分:总结与最佳实践
流程是不可逆的:知识库处理(向量化)是一次性的预处理步骤。而用户的每次提问都会触发后面的完整推理流程。
提示词工程是关键:系统提示词的质量直接决定答案的准确性。多迭代和测试你的提示词,比如要求模型“引用来源”、“分点回答”等。
向量数据库是必需的:对于任何有实际用途的知识库系统,向量数据库在性能和准确性上都是不可或缺的。
分块策略需要调试:块太大,会包含无关信息;块太小,会丢失上下文。这是需要根据你的数据源反复实验的。
成本考量:Embedding 和 Chat 都要收费。预处理知识库时会有一次性的 Embedding 成本。每次用户提问会触发 1 次 Embedding(问题) + 1 次 Chat。
安全性:不要将 API Key 暴露在前端,所有操作都应在你的 PHP 后端完成。
通过以上步骤,你就可以搭建一个真正理解你专业知识的、能够引用资料回答问题的智能体,而不仅仅是一个普通的聊天机器人。




发表评论 取消回复